






Have you ever wondered how AI voicebots sound so incredibly human-like?? The secret lies in the remarkable technology of Text-to-Speech (TTS) that takes written information and magically metamorphoses it into speech. Taking the form of a technical engine or a software system, TTS uses intricate machine learning algorithms along with elaborate linguistic models, resulting in speech that is astonishingly similar to natural human vocals.
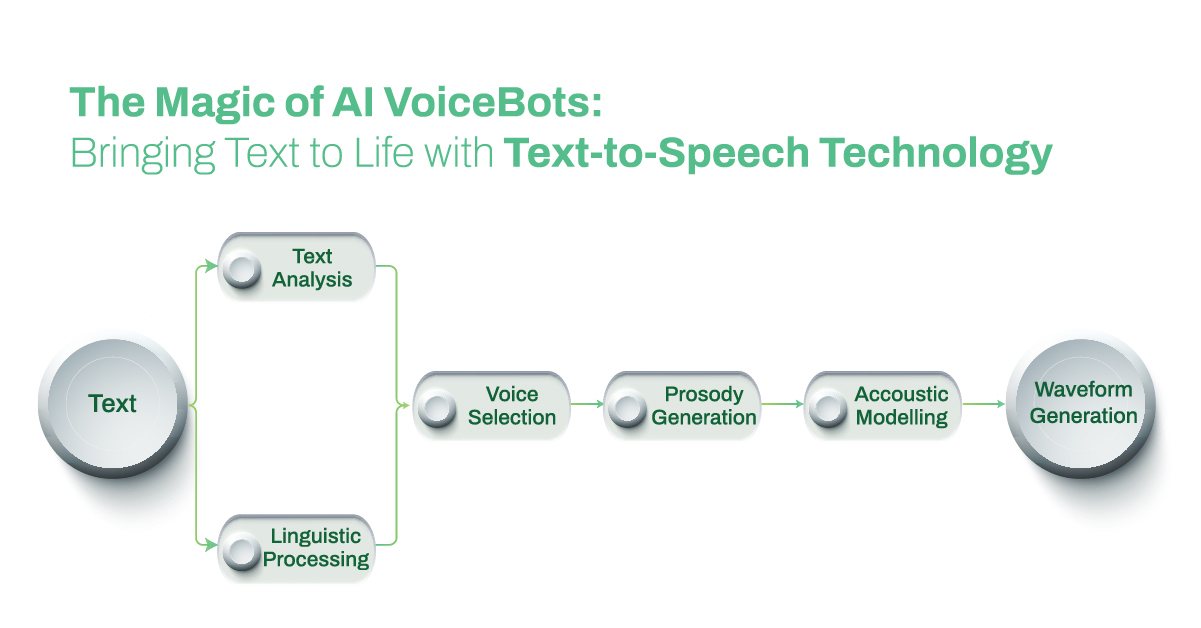
In the journey of shifting words on a page into human-like speech, several essential steps play prominent roles. During this conversion process, TTS engines meticulously analyze, process, and generate speech from text.
Let’s delve into the particular points to consider when selecting a Text-to-Speech model:
- Analyzing the Text: The first step in the TTS engine’s process is completing a rigorous textual analysis. The written input is deconstructed into smaller, more manageable segments such as phrases, sentences, and individual words. In parallel, crucial elements such as punctuation marks and sentence structure are identified, along with particular linguistic components like phonemes and prosody.
- Linguistic Processing: This stage utilizes linguistic models and rules that tell the TTS engine about the phonetic, syntactic, and semantic properties of the text. The engine parses through the text to determine varying pronunciations, identify stress patterns, and deduce the intonation.
- Leveraging Acoustic Models: Acoustic models hold significance as they forecast the speech waveform from the phonetic symbols. Under this process, a neural network or statistical model gets trained to associate unique phonemes with their corresponding acoustic characteristics like pitch, intensity, and duration.
- Generation of Prosody: Prosody in speech signifies aspects like rhythm, intonation and stress. To lend a natural tone to the synthesized speech, the TTS engine generates various prosodic features. These include scenarios of pitch contours, variances in the speech rate and emphasis to elicit an emotional response.
- Synthesis of Waveform: Utilizing both phonetic representations and prosodic information, the TTS engine then shifts into creating a continuous waveform that symbolizes the converted speech. This waveform acts as a digital audio signal that, once created, can be played via headphones or speakers.
- Voice: This stage provides users with the flexibility to select different voices. Multiple TTS engines offer a wide selection of voices, each associated with a distinct acoustic model, thus providing variations in pitch, tone, and style which can be altered to suit various preferences or applications.
- Final Playback and Output: The endpoint of this conversion cycle results in the synthesized digital audio signal, or waveform, being transmitted through audio output devices. This allows users to hear the speech that the TTS engine just transformed from the provided text.
Conclusion: More Than Just Technology
At Exotel, Text-to-Speech in our AI voicebots is more than just a feature; it’s a gateway to more human, more engaging, and more effective communication. It’s not just about the words spoken; it’s about the connection made. Join us in this exciting journey as we continue to redefine the future of conversation with our advanced AI voice bot technology.
Feel free to visit our previous AI Voicebot blogs:




